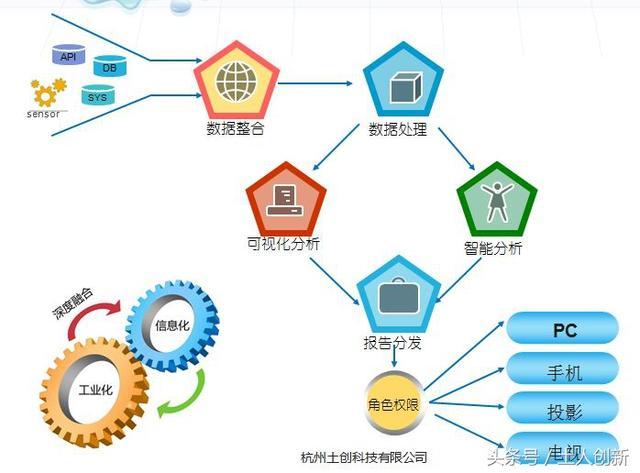
隨著工業4.0和智能制造浪潮的推進,工業大數據可視化系統已成為企業數字化轉型的核心工具。它不僅將海量、復雜、多維的工業數據轉化為直觀的圖表和儀表盤,更是連接物理世界與數字世界的橋梁,賦能管理者實現實時監控、精準分析和科學決策。本文將系統闡述如何建設一個高效、可靠、易用的工業大數據可視化系統。
一、明確業務目標與需求分析
任何系統的建設都應始于業務。需要與業務部門(如生產、設備、質量、能源部門)深入溝通,明確核心痛點與期望目標。例如,是希望降低設備非計劃停機時間、提升產品質量一致性、優化能源消耗,還是實現生產過程的透明化追溯?明確目標后,進一步梳理關鍵績效指標(KPI),并確定需要監控和分析的數據維度、顆粒度及實時性要求。
二、構建堅實的數據基礎架構
可視化是“冰山之上”的展現,其下需要強大的數據基礎支撐。
- 數據采集與接入:工業數據來源多樣,包括傳感器(IoT)、SCADA系統、MES、ERP、CRM等。需根據數據類型(實時流數據、時序數據、關系型數據)和協議(OPC UA、MQTT、Modbus等),選擇并部署相應的數據采集網關或代理,實現多源異構數據的統一接入。
- 數據存儲與管理:針對海量時序數據(如設備振動、溫度),采用時序數據庫(如InfluxDB、TDengine)以獲得高效的讀寫性能。對于關系型業務數據,可使用傳統關系型數據庫或數據倉庫。數據湖技術(如Hadoop、云對象存儲)可用于存儲原始數據,支持后續的探索性分析。建立統一的數據模型和數據資產目錄至關重要。
- 數據治理與質量:建立數據標準,對數據進行清洗、去重、糾錯和補全,確保數據的準確性、一致性和完整性。實施數據血緣追蹤和數據安全策略(如權限分級、脫敏)。
三、設計可視化系統架構
一個典型的分層架構包括:
- 數據源層:各類工業系統和傳感器。
- 數據采集與處理層:負責數據的實時攝取、流處理(如使用Apache Flink、Spark Streaming進行實時計算)和批量ETL。
- 數據存儲層:由時序數據庫、關系數據庫、數據湖等構成。
- 分析計算與服務層:提供數據查詢、分析模型(如預測性維護、能耗分析算法)和API服務。
- 可視化展現層:通過Web或大屏,向用戶提供交互式圖表、三維模型、地理信息等可視化界面。
四、核心可視化功能設計
可視化設計應遵循“簡潔、清晰、聚焦”的原則,避免信息過載。
- 全局概覽儀表盤:展示企業或工廠級核心KPI(如OEE、總產量、總能耗),一圖掌握全局狀態。
- 實時監控視圖:對生產線、關鍵設備的運行狀態(啟停、速度、報警)進行毫秒級實時刷新,支持地圖、流程圖、3D數字孿生模型等多種形式。
- 歷史數據分析:提供豐富的交互式圖表(折線圖、柱狀圖、散點圖、熱力圖),支持按時間、設備、產品批次等多維度下鉆、上卷和關聯分析,追溯歷史問題。
- 預警與報警中心:基于規則或機器學習模型,設定閾值,實現異常自動檢測與實時告警,并可視化報警分布和趨勢。
- 移動端適配:支持在手機、平板等移動設備上查看關鍵信息,滿足巡檢和移動辦公需求。
五、關鍵技術選型與開發
- 開發方式:可選擇成熟的商業BI工具(如帆軟、Tableau,可快速搭建),或采用開源可視化庫(如ECharts、D3.js、Three.js)進行自主開發,靈活性更高。工業場景常需二者結合。
- 前后端技術:前端主流框架如Vue.js、React;后端可選用Java、Python、Go等,提供RESTful API或WebSocket(用于實時數據推送)。
- 云平臺與微服務:考慮采用云原生架構,將系統拆分為松耦合的微服務(如數據采集服務、報警服務、報表服務),便于擴展和維護。利用云計算彈性資源應對數據峰值。
六、實施、部署與持續優化
- 迭代開發:采用敏捷開發模式,分階段交付,優先實現價值最高的功能模塊,并持續收集用戶反饋。
- 部署與集成:部署在私有云、公有云或混合云環境,并與現有IT/OT系統(如MES、ERP)深度集成,打破數據孤島。
- 用戶培訓與文化推廣:對一線操作員、工程師和管理者進行分層培訓,培養數據驅動決策的文化。
- 系統運維與迭代:建立監控體系保障系統穩定,并基于業務發展和技術進步,持續迭代可視化內容和分析模型。
###
建設工業大數據可視化系統是一項系統工程,技術是骨架,業務是靈魂。成功的核心在于以解決實際業務問題為導向,構建從數據到洞察的完整閉環。它不僅是一個“看”數據的工具,更應成為一個能夠“理解”數據、“預測”未來并輔助“行動”的智能中樞,最終驅動工業企業在效率、質量和創新上實現質的飛躍。